Inside MiniGPT: Building a Transformer Language Model from Scratch on Modest Hardware (4.6 M parameter model on CPU)

1. Introduction: From Recurrent Dreams to Transformer Realities
My journey into building language models began with the humble RNN. It was raw, educational, and full of limitations. But those limitations became the sparks for curiosity. With every vanishing gradient and limited memory scope, I began dreaming bigger. What if I could build a Transformer? Something modular, interpretable, and human-like in its outputs. This post is a continuation of that pursuit, which started as an RNN web app and has evolved into a compact Transformer inference engine I call MiniGPT.
This is the story of how I built MiniGPT from the ground up, complete with real-time token streaming, word-level tokenization, interactive frontend controls, and optimized performance, all on a consumer-grade CPU. Whether you’re an AI enthusiast or a builder craving full-stack ML experience, I hope this journey inspires you.
2. The Vision: Why Build a Custom Transformer?
I didn’t set out to beat GPT-2 or GPT-3. Instead, my goal was to understand every bolt of the Transformer. I wanted a system I could tweak, debug, and explain to others. Pretrained models like OpenAI’s are magical, but to me, magic without understanding is a missed opportunity.
Why word-level? Why 4 layers? Why stream with FastAPI? Because each of these was a decision I had to make intentionally. The outcome isn’t just MiniGPT, it’s the learning encoded in every architectural choice.
Transformer Architecture
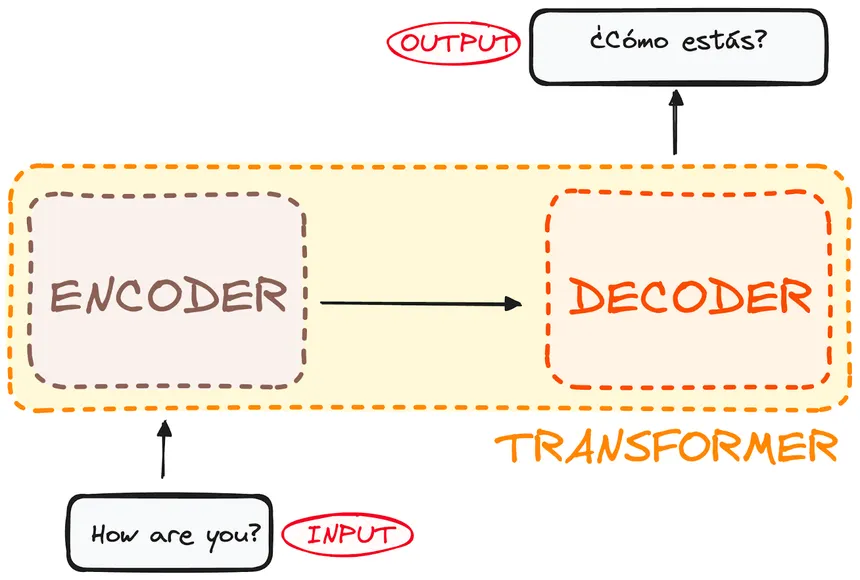
An easier representation of transformer
3. Designing MiniGPT: Architecture and Hardware Constraints
MiniGPT had to run efficiently on my hardware, an i5 CPU with 16GB RAM and an integrated Intel GPU. With that constraint in mind, I designed:
- 4 Transformer layers
- 4 attention heads
- 128 embedding dimensions
- 512 hidden feed-forward units
- Sequence length: 128 tokens
This strikes a balance between capability and cost. The model is small enough for real-time inference, but large enough to generate coherent short passages.
4. Tokenization Strategy: Making Every Word Count
My initial RNN used character-level tokenization. It worked, but lacked abstraction. Too much repetition, too little meaning. For MiniGPT, I moved to word-level tokenization using HuggingFace’s "tokenizers" library.
It wasn’t perfect, repetition still surfaced. But this time, I had a new weapon: Repetition Penalty. By applying dynamic penalties during sampling, I could push the model toward novel phrasing without destroying fluency.
5. Training & Inference Setup: Teaching the Mini Giant
Although I didn’t train from scratch, I used a saved checkpoint trained over 20,000 epochs on a small dataset to simulate incremental learning. Every 100 epochs, I checkpointed.
For inference, I sampled 20 tokens at a time to get a feel for the learning trajectory. This revealed whether the model was overfitting, memorizing, or genuinely learning language patterns.
6. Generation Control: Making Output More Human
Plain sampling wasn’t enough. I implemented the full sampling suite:
- Top-k sampling (cut off low-probability tokens)
- Top-p sampling (nucleus sampling)
- Temperature (softmax smoothing)
- Repetition penalty (discouraging loops)
These gave users creative control. But even with beautiful words, sentence coherence remained elusive. That’s the next frontier.
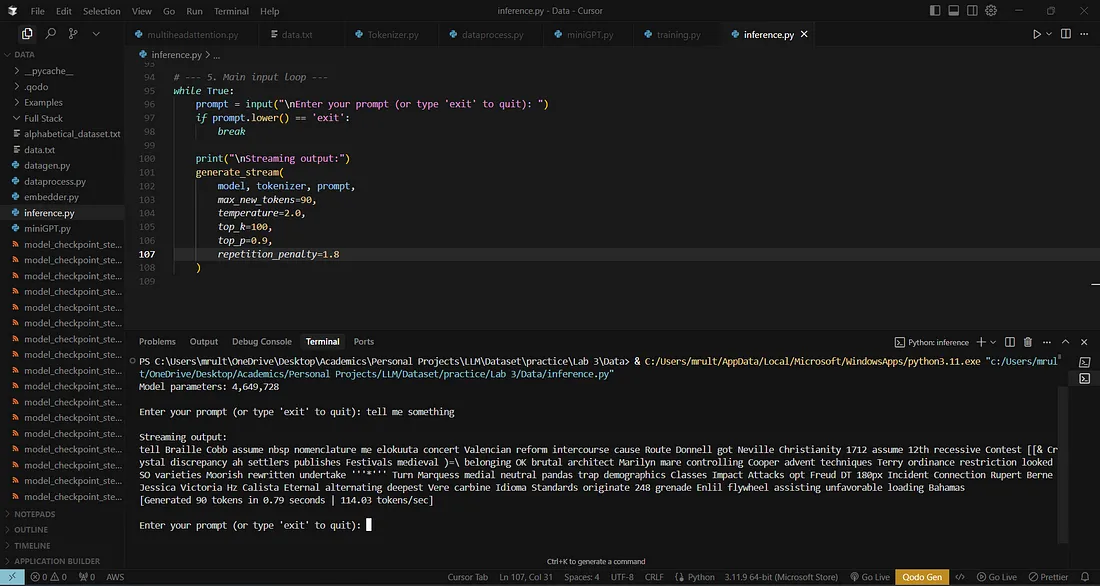
It still speaks like a baby.
7. Real-Time Streaming: Making Output Feel Alive
I integrated FastAPI with Server-Sent Events (SSE) to push each generated token to the frontend in real time. This makes the generation feel alive, like the AI is thinking as it types.
On the frontend, I used Microsoft’s streaming "fetch" capabilities to handle token-by-token rendering.
8. Frontend: Let the User Drive
My previous RNN app had a GUI, so I built on that foundation. The new interface includes:
- Model selector (RNN or Transformer)
- Sliders for temperature, top_k, top_p, repetition penalty, Temprature and Context length
- Real-time generation view
- Instant parameter update via React hooks
Rather than hiding the knobs behind code, I wanted the user to be the experimenter.
The integration between backend and frontend is still under development will be out soon.
9. Backend: The Inference Engine
The FastAPI backend powers it all:
/generate-streamendpoint for SSE- PyTorch Transformer inference
- Parameter validation & logging
- Built-in RNN model switcher for comparison
- CORS for frontend requests
This backend is robust enough for local use and could scale to small-scale deployment.
10. Performance & Debugging: Built for Modest Machines
From the start, this project was tuned for consumer hardware:
- Minimal RAM footprint (Uses around 5–6 GB for inference, 9–12 GB for training)
- Batch size = 1 for interactivity
- No GPU dependencies
- Efficient Python loops and vectorized sampling
Debugging was a major effort: from React race conditions to stale closures in streaming, it's almost done fixture will be out soon.
11. Key Learnings & Developer Takeaways
This project wasn’t just about code. It was about understanding:
- Transformer internals, multi-head attention, positional embeddings, layer normalization
- Sampling theory: How parameters shape creativity
- Real-time syncing: Managing frontend/backend latency and state
- Building alone: When you code alone, every layer, every bug becomes a teacher
12. Final Reflections: More Than a Mini Model
There’s a special kind of satisfaction in making everything work, from model to UI to streaming. MiniGPT is more than a toy, it’s a bridge from theory to application.
But this isn’t the end.
What’s Next? Recreating GPT-2 from Scratch
MiniGPT was just the warm-up. My next mission is far more ambitious: Rebuild GPT-2 from scratch, most likely follow Andrej Karpathy’s tutorial Let’s reproduce GPT-2 (124M), do check it
This means:
- Scaling to 12 or more layers
- Byte-pair encoding tokenizers
- Larger training corpus
- Deep dive into positional encoding innovations
- Multi-GPU training
I’ll document every step, from model design to tokenizer training to checkpoint sampling. Stay tuned, because this will be a true test of what I’ve learned, and a major leap forward.
If MiniGPT was about building a brain, GPT-2 will be about building a mind.